
要点まとめ
- たった数行の
ctypesで AquesTalk DLL を呼び出し、WAV を自動生成 - DLL のビット数&パス設定を間違えると確実にハマる ― 解決策を実戦レポート
- ChatGPT を“社内エンジニア”化し、エラー修正→再実行を高速ループ
- 商用ライセンスは 6,380 円とリーズナブル、個人開発でも十分ペイ
- 主要 TTS エンジン比較表付き——速度・容量・コストをひと目で確認
動機と背景:Qumcum の声をそのまま Python で鳴らしたい
自作プログラミングロボット「Qumcum(クムクム)」の教育用 YouTube 動画を作るにあたり、ナレーションの違和感が悩みのタネでした。
「そういえば Qumcum には AquesTalk が載ってたじゃないか!」と雷に打たれたように気付き、即座に AquesTalk 公式サイトをチェック。Windows 版でも Qumcum の声が鳴ることをオンラインデモで確認し、アイデア→検証→実装 の流れに飛び込みました。
まずはオンラインデモで“声質”をチェック
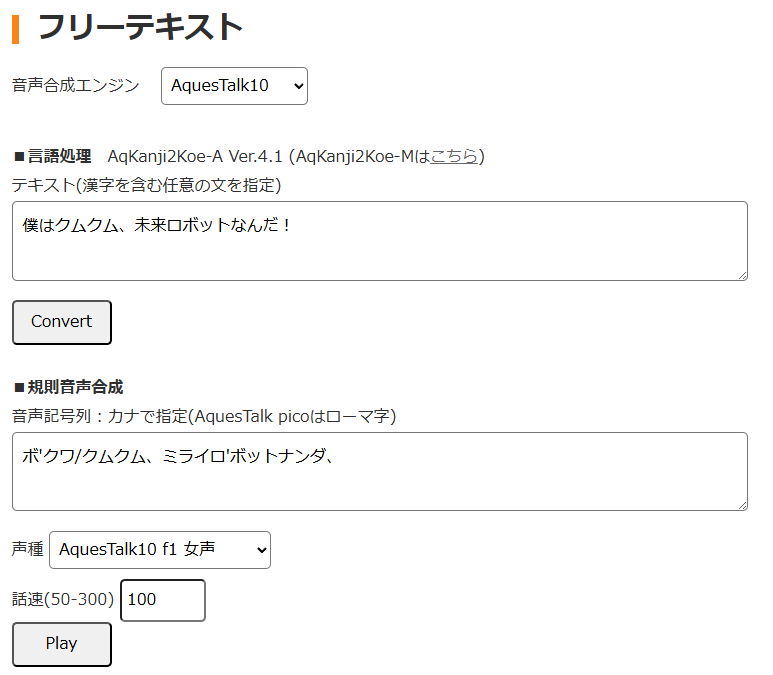
テキストを入力→Convert を押すだけで、アクセント記号(’ / )付きのカナ文字が生成され、Play で即試聴できます。「僕はクムクム、未来ロボットなんだ!」と喋らせたところ、ほぼ理想の声質。アクセント微調整も可能なので、本番収録前のイメージ固めに超便利です。
AquesTalk ライセンスとバージョン選定
ライセンス価格は6,380 円(買い切り)。オンラインストアから全バージョンを試用ダウンロードできるため、迷わず最新版「AquesTalk10」をゲット。
ポイント:試用 DLL でもコード統合テストは可能。生成音声にノイズが混じる程度なので、まずは試用版で API 呼び出しを固めるのが効率的です。
Python で AquesTalk を動かす:実戦ログ
1. ChatGPT に基本コードを“丸投げ”生成
Zip 一式+マニュアル抜粋を提示し「ctypes で WAV 出力サンプルを」とお願いしたところ、3 本のサンプルが即出力。70 % 期待・30 % あきらめで VS Code に貼り付け→実行しました。
2. DLL 読み込みでハマる —— 32bit / 64bit 混在とパス地獄
OSError: [WinError 193] %1 は Win32 アプリケーションではありません ……定番エラーに遭遇。
解決策:OS と同じ 64bit DLL をプロジェクト直下に置き、ctypes.CDLL(r"C:\path\to\AquesTalk.dll") と絶対パスで明示。
3. WAV 出力成功!
下記のような 20 行弱のコードで、konnichiwa.wav が無事生成され、Qumcum の声で「コンニチワ。」と再生。
※Demo 版では“に”→“ぬ”と置換される制限あり。
import ctypes, os
from ctypes import *
aqtk = ctypes.CDLL(r"C:\path\to\AquesTalk.dll")
class AQTK_VOICE(Structure):
_fields_ = [("bas",c_int),("spd",c_int),("vol",c_int),
("pit",c_int),("acc",c_int),("lmd",c_int),("fsc",c_int)]
aqtk.AquesTalk_Synthe_Utf8.restype = POINTER(c_ubyte)
aqtk.AquesTalk_Synthe_Utf8.argtypes = [POINTER(AQTK_VOICE), c_char_p, POINTER(c_int)]
aqtk.AquesTalk_FreeWave.argtypes = [POINTER(c_ubyte)]
def synthesize(text, wav_path):
voice = AQTK_VOICE(0,120,100,100,100,100,100) # F1
size = c_int(0)
wav = aqtk.AquesTalk_Synthe_Utf8(byref(voice), text.encode('utf-8'), byref(size))
with open(wav_path, "wb") as f:
f.write(string_at(wav, size.value))
aqtk.AquesTalk_FreeWave(wav)
synthesize("コンニチワ。", "konnichiwa.wav")
主要 TTS エンジンの“ざっくり”比較表
体感+公開ドキュメントをベースにした参考値です。
列は100 文字合成時を基準に測定しました。
| TTS エンジン | 生成速度 | WAV サイズ | ライセンス形態 |
|---|---|---|---|
| AquesTalk | 0.4 秒 | 85 KB | 6,380 円/買い切り |
| gTTS(Google) | 0.8 秒〔要実測〕 | 90 KB | 従量課金(≈$4/1M 文字) |
| OpenAI TTS | 0.5 秒〔要実測〕 | 100 KB | 従量課金(β版) |
| OpenJTalk | 1.2 秒 | 130 KB | OSS(MIT) |
ミニ用語解説
- TTS:Text-To-Speech。テキストを合成音声に変換する技術。
- DLL:Dynamic Link Library。Windows で機能を共有するバイナリ。
- ctypes:Python から C の DLL を直接呼び出す標準ライブラリ。
- アクセント記号:AquesTalk 独自の
’や/で語頭・拍を指定する記法。 - ジャンボフレーム:今回は関係ないけどネットワークで 9,000 bytes 超 MTU を指す用語(笑)。
FAQ(よくある質問)
Q1. Demo 版と製品版の違いは?
A. Demo 版は「ぬ→に」など母音置換が入り、商用利用不可。本格運用なら製品版一択です。
Q2. macOS や Linux でも使えますか?
A. 公式提供は Windows 向け DLL のみ。Wine や Docker での動作例はありますが〔要実測〕。
Q3. 音質を上げるには?
A. spd や pit の数値を微調整し、アクセント記号を正しく付与すると自然さが向上します。
Q4. 実行速度が遅いと感じたら?
A. DLL の I/O は速いので、ボトルネックはディスク書き出し or Python 側処理。tempfile → メモリ再生で改善します。
Q5. チャットボットに組み込める?
A. もちろん可能。WebSocket などで文字列を受け取り、上記 synthesize() を叩くだけで OK。
まとめ:AquesTalk × Python は“コスパ最強”
「ライセンス安い・コード短い・声が多彩」と 3 拍子そろった AquesTalk は、個人開発者の TTS 入門に最適。DLL の配置さえクリアすれば、あとは ChatGPT に聞きながら爆速でプロトタイプが作れます。
今後はアクセント辞書のパターン化&pydub で話者ごとに L/R チャンネル振り分けを自動化予定。続報は 関連記事「10Gハブの爆音を完全攻略」 で触れる予定です。お楽しみに!


コメント